








5/2/2023
PITTSBURGH — In a paper published today in Communications Biology, auditory neuroscientists at the University of Pittsburgh describe a machine learning model that helps explain how the brain recognizes the meaning of communication sounds, such as animal calls or spoken words.
The algorithm described in the study models how social animals, including marmoset monkeys and guinea pigs, use sound-processing networks in their brain to distinguish between sound categories – such as calls for mating, food or danger — and act on them.
The study is an important step toward understanding the intricacies and complexities of neuronal processing that underlies sound recognition. The insights from this work pave the way for understanding, and eventually treating, disorders that affect speech recognition, and improving hearing aids.
“More or less everyone we know will lose some of their hearing at some point in their lives, either as a result of aging or exposure to noise. Understanding the biology of sound recognition and finding ways to improve it is important,” said senior author and Pitt assistant professor of neurobiology Srivatsun Sadagopan, Ph.D. “But the process of vocal communication is fascinating in and of itself. The ways our brains interact with one another and can take ideas and convey them through sound is nothing short of magical.”
Humans and animals encounter an astounding diversity of sounds every day, from the cacophony of the jungle to the hum inside a busy restaurant. No matter the sound pollution in the world that surrounds us, humans and other animals are able to communicate and understand one another, including pitch of their voice or accent. When we hear the word “hello,” for example, we recognize its meaning regardless of whether it was said with an American or British accent, whether the speaker is a woman or a man, or if we’re in a quiet room or busy intersection.
The team started with the intuition that the way the human brain recognizes and captures the meaning of communication sounds may be similar to how it recognizes faces compared with other objects. Faces are highly diverse but have some common characteristics.
Instead of matching every face that we encounter to some perfect “template” face, our brain picks up on useful features, such as the eyes, nose and mouth, and their relative positions, and creates a mental map of these small characteristics that define a face.
In a series of studies, the team showed that communication sounds may also be made up of such small characteristics. The researchers first built a machine learning model of sound processing to recognize the different sounds made by social animals. To test if brain responses corresponded with the model, they recorded brain activity from guinea pigs listening to their kin’s communication sounds. Neurons in regions of the brain that are responsible for processing sounds lit up with a flurry of electrical activity when they heard a noise that had features present in specific types of these sounds, similar to the machine learning model.
They then wanted to check the performance of the model against the real-life behavior of the animals.
Guinea pigs were put in an enclosure and exposed to different categories of sounds — squeaks and grunts that are categorized as distinct sound signals. Researchers then trained the guinea pigs to walk over to different corners of the enclosure and receive fruit rewards depending on which category of sound was played.
Then, they made the tasks harder: To mimic the way humans recognize the meaning of words spoken by people with different accents, the researchers ran guinea pig calls through sound-altering software, speeding them up or slowing them down, raising or lowering their pitch, or adding noise and echoes.
Not only were the animals able to perform the task as consistently as if the calls they heard were unaltered, they continued to perform well despite artificial echoes or noise. Better yet, the machine learning model described their behavior (and the underlying activation of sound-processing neurons in the brain) perfectly.
As a next step, the researchers are translating the model’s accuracy from animals into human speech.
“From an engineering viewpoint, there are much better speech recognition models out there. What’s unique about our model is that we have a close correspondence with behavior and brain activity, giving us more insight into the biology. In the future, these insights can be used to help people with neurodevelopmental conditions or to help engineer better hearing aids,” said lead author Satyabrata Parida, Ph.D., postdoctoral fellow at Pitt’s department of neurobiology.
“A lot of people struggle with conditions that make it hard for them to recognize speech,” said Manaswini Kar, a student in the Sadagopan lab. “Understanding how a neurotypical brain recognizes words and makes sense of the auditory world around it will make it possible to understand and help those who struggle.”
An additional author of the study is Shi Tong Liu, Ph.D., of Pitt.
This work was supported by the National Institutes of Health (grant R01DC017141).
PHOTO DETAILS: (click image for high-res version)
CREDIT: Manaswini Kar
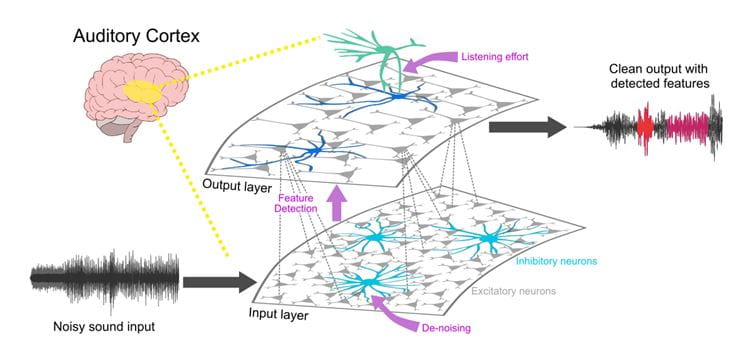
CAPTION: Noisy sound inputs pass through networks of excitatory and inhibitory neurons in the auditory cortex that clean up the signal (in part guided by the listener paying attention) and detect characteristic features of sounds, allowing the brain to recognize communication sounds regardless of variations in how they are uttered by the speaker and surrounding noise.
